[转]CCERT中文垃圾邮件过滤规则集 Chinese_rules.cf
CCERT中文垃圾邮件过滤解决方案 CCERT-Anti-Spam-Solutions-v2.pdf
1. 什么是 Chinese_rules.cf
Chinese_rules.cf是用于业界广泛使用的免费垃圾邮件过滤系统SpamAssassin的中文垃圾邮件过滤规则集。由于以前没有中文的过滤规则集,SpamAssassin对中文邮件过滤的准确性不高。CCERT反垃圾邮件研究小组利用CCERT所掌握的最新和丰富的样本数据,推出了第一个基于SpamAssassin的中文垃圾邮件过滤规则集Chinese_rules.cf。该规则集每周更新一次,时效性非常好。
Chinese_rules.cf是在SpamAssassin 官方网站上发布的第一个中文垃圾邮件过滤规则集,也是用Google,Yahoo,百度,MSN搜索“中文垃圾邮件过滤”时所返回的第一条结果。
2. Chinese_rules.cf的理论背景
Chinese_rules.cf是邮件内容过滤规则集。目前邮件内容过滤技术可以分为两种方法:基于规则和基于统计的方法。基于规则的方法就是在邮件内容中寻找特定的模式,例如主题包含“免费”。基于统计的就是使用统计方法解决邮件的二元分类问题,其中分类机跟据垃圾邮件和正常邮件的样本训练出来。在垃圾邮件过滤技术中最常用的统计方法就是贝叶斯准则。
基于规则方法的优点是规则可以共享,因此它的推广性很强。一个人写出的规则可以提供给多个人,多个服务器使用。然而它的缺点就是更新速度慢。因为规则一般都是人工编写生成,所以新规则的产生速度跟不上新垃圾邮件出现的速度,换句话说,它的时效性较差。
基于统计的方法的优点就是分类机由程序自动训练出来,只要及时更新样本训练集就可以使分类机更新的速度跟得上垃圾邮件出现的速度,即它的时效性很强。然而该方法的缺点就是分类机不能共享,某个用户用自己的邮件样本集训练出来的分类机对其他用户可能效果不佳,因此该方法的推广性较差。
Chinese_rules.cf使用基于统计规则的新方法,即它所使用的规则是由统计方法自动生成的。该方法吸取了基于规则和基于统计的优点:因为它是一种基于规则的方法,因此推广性很强,又因为它的规则是由统计方法自动生成的,因此它的时效性也很强。Chinese_rules.cf和传统方法比较如表1所示。
表1、Chinese_rules.cf和传统方法比较
| 推广性 | 时效性 | |
| 基于规则 | 好 | 差 |
| 基于统计 | 差 | 好 |
| Chinese_rules.cf | 好 | 好 |
CCERT反垃圾邮件组自从1998年成立以来,每天都处理大量的垃圾邮件投诉,掌握最新和最丰富的样本数据。Chinese_rules.cf就在此最新和最丰富的样本数据库的基础上,通过统计方法自动产生的。
3. Chinese_rules.cf的生成和使用框架
Chinese_rules.cf的生成和使用框架如图1所示。首先,利用CCERT垃圾邮件处理服务和用户反馈信息来维护一个最新,最全的垃圾/正常邮件样本库,再利用统计方法,根据垃圾/正常邮件样本库自动生成规则集Chinese_rules.cf。CDSCE是该样本库的一个公开版本.因为样本库是最新的,Chinse_rules.cf的时效性就非常强。CCERT把该规则集在CCERT主页上发布,作为CCERT提供的一种对外服务。各地用户(服务器)通过CCERT主页下载Chinese_rules.cf,这样使Chinese_rules.cf的推广性很强。
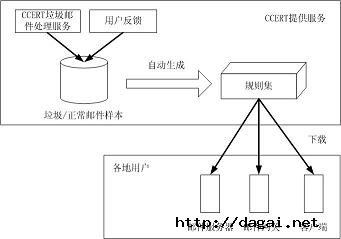
图1、Chinese_rules.cf 的生成和使用框架
4. Chinese_rules.cf的匹配速度问题
Chinese_rules.cf规则集一般被控制在500个规则左右。这一数字也许使人对Chinese_rules.cf的匹配速度有点置疑。仔细分析和测试结果表明Chinese_rules.cf的匹配性能还是比较高的,原因是:一、Chinese_rules.cf的规则都很简单,都是一个比较短的字符串,中间没有带任何一个通配符,这样匹配速度比复杂的规则要快的多;二、Chinese_rules.cf中有90%是邮件主题的规则,只有10%是信体的规则。由于邮件主题往往比较短,因此Chinese_rules.cf的匹配速度会比较快。
以上是对性能的理论分析。我们用一台普通PC(P4 2.8G CPU),用Chinese_rules.cf (2004
Dec 21的版本) 对178482封邮件匹配,则结果是平均匹配一封大小为5.0K的邮件只需要 0.04秒。这个结果实非常好的,因为如果一个邮件服务器的邮件平均大小为5.0K(不算附件),那么只要一台普通PC每天就可以处理216万封邮件。一般的学生邮件服务器每天收发30万封左右。换句话说,只要在现有的邮件服务器加上如同上述一台PC的处理性能就足以满足处理垃圾邮件的硬件需求。
5. Chinese_rules.cf 的准确率
Chinese_rules.cf的每一个版本都带有对准确率的测试结果。当前版本的测试结果如下:
Chinese_rules.cf,2006 Oct 1
|
|
||
| 阈值 | 垃圾邮件查全率 (共121824) |
正常邮件误判率 (共207961) |
|
|
||
| 0.5 | 82.8% | 1.3% |
| 1.0 | 78.2% | 0.5% |
| 1.5 | 74.5% | 0.2% |
| 2.0 | 71.6% | 0.1% |
| 2.5 | 69.4% | 0.0% |
| 3.0 | 67.3% | 0.0% |
| 3.5 | 64.6% | 0.0% |
| 4.0 | 62.6% | 0.0% |
| 4.5 | 61.6% | 0.0% |
|
|
||
扫描一封邮件大小为 1434.4620 字节需要 0.0165 秒(P4-2.8G CPU)
表2中的结果就是在测试规程中,除了Chinese_rules.cf 以外不使用其他任何规则。在实际情况,Chinese_rules.cf一般都会跟SpamAssassin的缺省规则同时使用。因为SpamAssassin的缺省规则中有一部分是描述邮件行为的规则,对检测中文垃圾邮件起作用,因此实际的性能会比以上实验结果要好。
注意、 对于每天处理40万封邮件以上的邮件服务器来说,能够容忍的性能是正常邮件误判率小于5%的同时,垃圾邮件的检测率大于90%。
6. Chinese_rules.cf 的用户统计
CCERT于2004年9月7日在网上发布Chinese_rules.cf。图2就是用户查看规则集的统计(按IP)。可以看出规则集的知名度在直续上升。
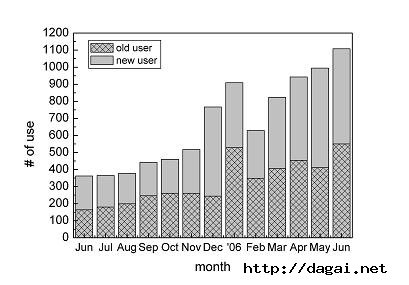
图2、用户查看规则集统计(按IP)
图3就是在Unix/Linux服务器上使用的用户统计(安不同IP),其中深灰色表示老客户,即上个月已经出现的IP。
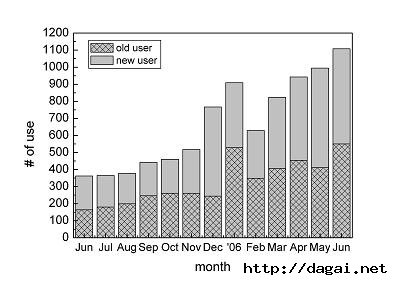
图3、用户使用规则集统计(按不同IP)
7. Chinese_rules.cf 的使用方法
下载Chinese_rules.cf,把该规则放在SpamAssassin存放规则的目录(一般在/usr/share/spamassassin)。通过wget下载的命令如下:
# wget -N -P /usr/share/spamassassin www.ccert.edu.cn/spam/sa/Chinese_rules.cf
每次更新Chinese_rules.cf都需要重启加载SpamAssassin规则的程序。如果你用spamd则通常重启的方法是:
# ps –ax | grep spamd
察看spamd进程的PID,然后
# kill -HUP PID
如果你用mimedefang则要重起mimedefang。假设mimedefang的重起脚本为 /etc/init.d/init-script,
则命令如下:
# /etc/init.d/init-script restart
CCERT每周更新一次规则集和相应分数,更新使用CCERT反垃圾邮件服务在6个月内处理过的垃圾邮件为样本。经常更新Chinese_rules.cf会使过滤效果更好。只要把上述下载命令以及重起mimedefang的命令放在crontab中,并定期运行就可以完成自动更新功能。假如你想一个月更新一次,那么在root的crontab中应该添加一行:
0 0 1 * * wget -N -P /usr/share/spamassassin www.ccert.edu.cn/spam/sa/Chinese_rules.cf;
/etc/init.d/init-script restart
更多信息请参见CCERT中文垃圾邮件解决方案 CCERT-Anti-Spam-Solutions-v2.pdf

2012/10/02 22:07:46
搞技术的就是不简单!